Subsections of Network
Docker
Subsections of Docker
Docker Netzwerk isolieren mit Firewall
Idee
Die Idee ist, einem oder mehreren Containern des gleichen Kontexts entsprechende Zugriffe auf andere Container / Netze zu geben. Dies schützt davor, dass ein “gehackter” Container nicht per se auf andere Dienste zugreifen kann. Man minimiert somit die Gefahr einer Kaskade weiterer Attacken.
Konkrete Beispiele für die Isolation, die einzelne Freigaben benötigen können Dienste wie Datenbanken, SMTP Server, oder auch HTTP/S Requests ins Internet sein.
Alle Zugriffe zwischen den Docker-Netzen, oder an andere Netze, können somit gezielt freigegeben oder unterbunden werden. Dieses Verfahren ist zwar anfänglich aufwendiger und es werden auch eventuell Probleme bei der Einrichtung von Containern auftreten, allerdings kann man die Kommunikation besser prüfen (loggen).
Zusätzlich ist das Unterbinden von Zugriffen in das Internet, oder das “nach Hause Telefonieren” einfacher …
Warnung
Die hier verwendeten Informationen sind Beispiele und können bei falscher Anwendung zu Netzwerkunterbrechung führen!
Netzwerk
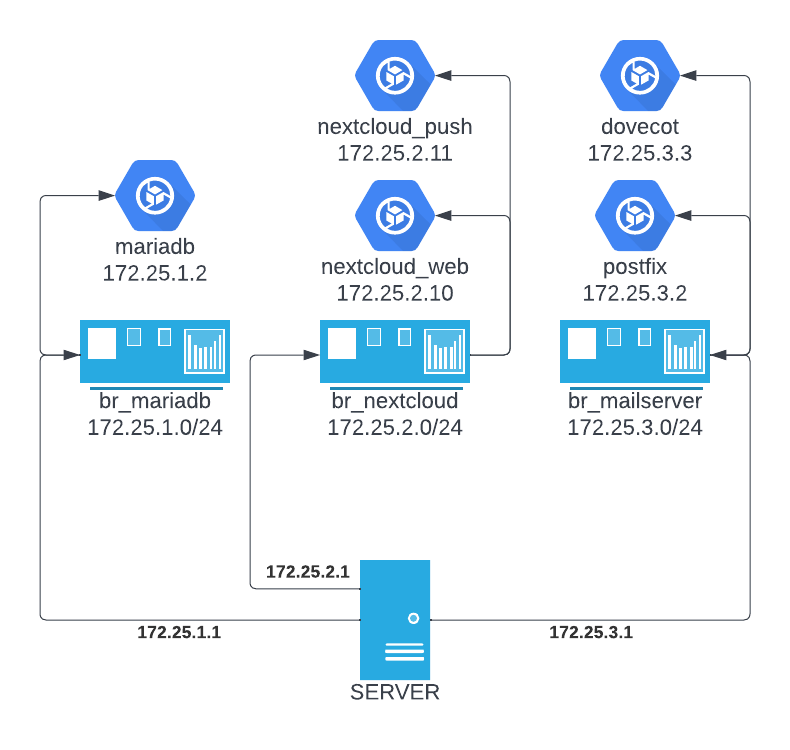
In diesem Beispiel werden mittels Docker 3 Bridges angelegt, jede mit einem eigenen /24er Netz, und entsprechenden Containern die eine IP aus dem jeweiligen Netz bekommen. Diese werden statisch festgelegt und sind somit eindeutig und bleibend, selbst wenn Container neu erstellt werden. Ein /24 ist verhältnismäßig groß, dient aber der einfacheren Handhabung und kann bei Bedarf auch verkleinert werden.
Grafik des Netzwerks- / der Container-Struktur
Docker-Compose
Warnung
Die hier gezeigten docker-compose.yml Dateien sind nur exemplarisch und nicht ohne Anpassung zu verwenden. Das liegt unter anderem an fehlenden Volume-Mounts und Environment-Variablen! Werden diese Dateien dennoch genutzt, ist mit anschließendem Datenverlust zu rechnen!
MariaDB
# File: /srv/docker/mariadb/docker-compose.yml
---
version: "3"
services:
mysql:
image: mariadb:10.4
container_name: mariadb
environment:
TZ: "UTC"
MYSQL_ROOT_PASSWORD: "xxxxxxxxxxx"
volumes:
- /srv/containers/mariadb/data:/var/lib/mysql:rw
restart: unless-stopped
networks:
default:
ipv4_address: 172.25.1.2
networks:
default:
driver: bridge
ipam:
driver: default
config:
- subnet: 172.25.1.0/24
driver_opts:
com.docker.network.bridge.name: br_mariadbNextcloud
# File: /srv/docker/nextcloud/docker-compose.yml
---
version: "3"
services:
web:
container_name: nextcloud
image: nextcloud:25-fpm
networks:
default:
ipv4_address: 172.25.2.10
push:
container_name: nextcloud_push
image: nextcloud:25-fpm
networks:
default:
ipv4_address: 172.25.2.11
networks:
default:
driver: bridge
ipam:
driver: default
config:
- subnet: 172.25.2.0/24
driver_opts:
com.docker.network.bridge.name: br_nextcloudMailserver
# File: /srv/docker/mailserver/docker-compose.yml
---
version: "3"
services:
postfix:
container_name: dovecot
image: dovecot_image
networks:
default:
ipv4_address: 172.25.3.2
postfix:
container_name: postfix
image: postfix_image
networks:
default:
ipv4_address: 172.25.3.3
networks:
default:
driver: bridge
ipam:
driver: default
config:
- subnet: 172.25.3.0/24
driver_opts:
com.docker.network.bridge.name: br_mailserverFirewall
Erklärung
Container im eigenen Layer2-Netz (Bridge) können untereinander sprechen, ohne dass eine Filterung durch die Firewall (Layer3) möglich ist.
Sollen Container außerhalb des eigenen Netzwerks (Subnets) miteinander sprechen, müssen Pakete geroutet werden. Dies übernimmt der Host auf dem die Container laufen. Dies ist möglich weil auf den Bridges selbst eine IP-Adresse (.1) gebunden ist und diese als Standardgateway in den Containern hinterlegt ist.
Beispiel
Nextcloud_web (172.25.2.10) muss mit der Mariadb (172.25.1.2) sprechen und weil diese nicht im selben Subnetz sind, routet der Container die Anfrage über sein Standardgateway (172.25.2.1).
Das Host-Netzwerk (Host Namespace) kennt wiederum den Weg zum MariaDB-Container, weil er selbst Mitglied im Netzwerk ist (172.25.1.1).
Erklärung was Linux Namespaces sind: https://en.wikipedia.org/wiki/Linux_namespaces (siehe Network Namespace).
Konfiguration
Routing
Routing muss aktiviert sein, was im Normalfall durch Docker passiert sein sollte.
Es kann aber im Zweifel folgenderweise aktiviert werden:
net.ipv4.ip_forward=1
sysctl -p /etc/sysctl.d/99-routing-enable.confDocker Daemon
Danach ist die Kommunikation grundlegend erst mal erlaubt, sofern Docker mit eigenen Firewall-Regeln dies nicht unterbindet. Nun kann der Docker Daemon konfiguriert werden, damit dieser die Firewall-Regeln mittels iptables nicht mehr anlegt ():
{
"iptables": false
}Falls bereits Inhalte in der Datei hinterlegt sind, muss die JSON Datei ergänzt werden. Danach kann Docker restarted werden, allerdings werden existente Firewall-Regeln nicht abgeräumt. Es kann also ein Reboot / Aufräumen nötig sein…
NFTables
Installation
pacman -Syu nftablesapt-get update; apt-get install nftablesFirewall Regeln
Warnung
Die hier gezeigten Regeln sind Beispiele und sollte nicht komplett kopiert werden!
Falsche handhabung kann zu Störungen im Netzwerk führen!
#!/usr/bin/nft -f
flush ruleset
table inet filter {
chain forward {
type filter hook forward priority 0;
# hergestellte Verbindungen werden direkt durchgelassen
ct state { established, related } accept
# erlaubt nextcloud_web mariadb zu erreichen, auf Port 3306
iifname br_nextcloud ip saddr 172.25.2.10 \
oifname br_mariadb ip daddr 172.25.1.2 tcp dport 3306 accept
# erlaube SMTP in das Internet (eth0 ist Internet-Interface)
# hierbei wird nicht nur der Versand (25), sondern auch
# SSL (465) und Submission (587) freigeschaltet
iifname br_nextcloud ip saddr 172.25.2.10 \
oifname eth0 tcp dport { 25, 465, 587 } accept
# Versand über Postfix Container
iifname br_nextcloud ip saddr 172.25.2.10 \
oifname br_mailserver ip daddr 172.25.3.2 tcp dport 465 accept
# Abrufen der Mails mittels Nextcloud Webmail Plugin (via IMAP)
iifname br_nextcloud ip saddr 172.25.2.10 \
oifname br_mailserver ip daddr 172.25.3.2 tcp dport { 143, 993 } accept
# Mariadb Verbindung von Dovecot und Postfix an Mariadb
iifname br_mailserver ip saddr { 172.25.3.0/24 } \
oifname br_mariadb ip daddr 172.25.1.2 tcp dport 3306
}
}Sets / Mappings
Eine weitere Möglichkeit um weniger Regeln zu definieren, ist die Verwendung von Mappings und Sets, denn jede Regel kostet Rechenzeit.
Sets können sowohl anonym (mittels “{}”) , als auch mit festem Namen angelegt werden.
Der Vorteil von Sets mit Namen ist, dass diese zur Laufzeit ergänzt, oder Einträge gelöscht werden können.
Hier ein Beispiel für die Freischaltung von Containern. Wichtig sind die Kommata hinter den Einträgen (elements). Kommentare in eigenen Zeilen sind nur möglich, wenn ein Komma vorransteht, weil es sich dann um ein “leeres” Element handelt.
Sets alleine schalten noch nichts frei, sondern sind Sammlungen von Keys die aus verschiedenen Datentypen bestehen können. Bis zu 5 Typen kann man kombinieren und prinzipiell sind alle NFT-Datentypen möglich. Diese werden dann von Regeln geprüft, ob die Kombination im Set enthalten ist. Was am Ende passiert, hängt vom Urteil der Regel ab (accept, drop, …).
#!/usr/bin/nft -f
flush ruleset
table inet filter {
# erlaube Transfer in das Internet für bestimmte Ports
# Kombination aus SRC_IP + SRC_INTERFACE + DEST_IP + PROTOCOL + PORT
set fwd_docker_to_wan {
type ipv4_addr . ifname . ipv4_addr . inet_proto . inet_service
flags interval
counter
elements = {
, # SMTP Versand
172.25.3.2 . "br_mailserver" . 0.0.0.0/0 . tcp . 25,
, # HTTPS zum Aktualisieren von Addons
172.25.3.2 . "br_nextcloud" . 0.0.0.0/0 . tcp . 443, # weiterer Kommentar
}
# erlaubt Traffic zwischen Containern
# Kombination aus SRC_IP + DEST_IP + PROTOCOL + PORT
set fwd_docker_accept {
type ipv4_addr . ipv4_addr . inet_proto . inet_service;
flags interval
counter
elements = {
172.25.3.2 . 172.25.1.2 . tcp . 3306, # Postfix zu Mariadb
172.25.2.10 . 172.25.1.2 . tcp . 3306, # Nextcloud zu Mariadb
172.25.2.10 . 172.25.3.3 . tcp . 143, # Nextcloud Dovecot
172.25.2.10 . 172.25.3.3 . tcp . 993, # Nextcloud Dovecot
}
}
chain forward {
type filter hook forward priority 0;
# hergestellte Verbindungen werden direkt durchgelassen
ct state { established, related } accept
# erlaubt Kombinationen die im Set fwd_docker_accept enthalten sind
ip saddr . ip daddr . meta l4proto . th dport \
@fwd_docker_accept accept
# erlaubt Kombinationen die im Set fwd_docker_to_wan enthalten sind
oifname eth0 ip saddr . iifname . ip daddr . meta l4proto . th dport \
@fwd_docker_to_wan accept
# sonstiger Transfer wird gedroppt und geloggt
# einsehbar mittels dmesg
log drop
}
}Eine Auflistung möglicher Datentypen kann hier eingesehen werden: https://wiki.nftables.org/wiki-nftables/index.php/Data_types. Diese können miteinander kombiniert werden, allerdings ist dies auf maximal 5 Datentypen beschränkt. Nutzt man mehr, wird das Set auf 5 Typen reduziert und wird fehlerhaft konfiguriert.
Das eine größere Menge nicht vorgesehen ist, lässt sich im Quellcode der nftables Binary gut erkennen: https://github.com/google/nftables/blob/0dda43a5f98c5bcb2a2a3f0de3c9adf458fa45f5/set.go#L193
Masquerading (Source NAT)
Falls ein Container in das Internet kommunizieren soll, muss noch an ein eventuell notwendig sMasquerading (Source NAT) gedacht werden. Beispiele finden sich im Internet zu genüge, aber soll hier nicht unerwähnt bleiben:
table ip nat {
chain postrouting {
type nat hook postrouting priority srcnat; policy accept;
oifname eth0 masquerade
}
}Man kann die Postrouting Regel auch genauer einstellen und auch die Quell-IP berücksichtigen, allerdings filtert die Forwarding Chain bereits den Traffic, sodass es an dieser Stelle doppelt wäre.
Es bietet sich hier auch die Nutzung von sogenannten Markierungen an, diese können beim Forwarding angeheftet werden und im späteren Verlauf von Regeln berücksichtigt werden: https://wiki.nftables.org/wiki-nftables/index.php/Matching_packet_metainformation
Testen der Regeln
nft -c -f /etc/nftables.confTreten Fehler auf, sollten Kommata, Klammern und Referenzen wie Variablen, Setnamen geprüft werden. NFTables gibt in der Regel konkrete Fehlermeldungen zurück.
Regeln laden & Autostart aktivieren
systemctl restart nftables
# Autostart für nftables aktivieren
systemctl enable nftablesZugriff auf Docker Network Namespace vom Host-System aus
Warnung
Die Befehle sind mit Root-Rechten durchzuführen und können bei falscher Handhabung zu Netzwerkproblemen führen!
Vorwort
Erklärungen zum Thena Linux Network Namespaces finden sich im Internet, beispielsweise:
- https://www.man7.org/linux/man-pages/man7/network_namespaces.7.html
- https://www.sobyte.net/post/2021-10/learn-linux-net-namespace/
Docker Netzwerke werden durch Namespaces repräsentiert und ermöglichen damit die Isolation der Container.
Im Gegensatz zu händisch angelegten Namespaces können diese aber nicht per ip netns Befehl aufgelistet, oder betreten werden.
Hierzu muss erst eine Verlinkung erstellt werden, damit man den Weg in den Namespace definiert…
Wofür wird das ganze benötigt?
Zum Debuggen kann es sehr hilfreich sein, wenn man statt den Container zu betreten (docker exec), den Network Namespace betritt.
Denn im Container selbst ist auch das Dateisystem isoliert.
Durch das Betreten des Network Namespaces stehen alle Tools aus dem Hostsystem zur Verfügung.
Das ist immer dann nützlich, wenn Anwendungen im Container nicht zur Verfügung stehen (z.B. tcpdump, ip, ssh, ss, netstat, …).
Wichtig zu wissen:
Durch den Wechsel des Network Namespaces, sind anderen Namespaces davon unberührt geblieben und z.B. Prozess-IDs bei Tools wie netstat können nicht korrekt angezeigt werden, oder Fehlermeldungen auftreten… Man hat eben nur die Netzwerkumgebung gewechselt …
Zugriff auf Namespace
- Container ID ermitteln (ID steht ganz vorne)
docker ps | grep <NAME>
container_id="xxxxxxxxxxx"- Process ID des Containers ermitteln
pid=$(docker inspect -f '{{.State.Pid}}' ${container_id})- Namespace-Verknüpfung anlegen
mkdir -p /var/run/netns/
ln -sfT /proc/$pid/ns/net /var/run/netns/${container_id}- Verfügbarkeit prüfen
ip netns | grep ${container_id}- Zugriff auf den Namespace
ip netns exec ${container_id} ip aMöchte man eine Shell im Namespace starten geht das auch:
ip netns exec ${container_id} bashMan kann durch beenden des Befehls (Schließen der Shell) wieder in den Host Namespace wechseln, entweder mit “STRG + D” oder dem Befehl exit!
Linux
Subsections of Linux
Firewall Freischaltung mittels Wesberver Log
Möchte man Besucher für Dienste (Ports) freischalten, kann beispielsweise ein Webserver-Log herangezogen werden und auf Grundlage des HTTP-Status-Codes eine Freischaltung erfolgen. Hierzu ein einfaches Skript als Beispiel, das je nach Bedarf angepasst werden kann.
#!/usr/bin/bash
# Datei zum auslesen der Zugriffe
file="/var/log/nginx/my-host.access.log"
while true; do
# Datei folgend öffnen, filtern und zeilenweise lesen
tail -n1 -F "${file}" --retry | grep --line-buffered '"GET / HTTP/1.1" 200' | while read line;do
# IP-Adresse aus der Zeile extrahieren (Split nach Leerzeichen)
ip=${line%% *};
echo "whitelisting IP [$ip]";
# Hinzufügen der IP-Adresse in IP-Set myset mit 24 Stunden Timeout
nft add element inet filter myset { ${line%% *} timeout 24h };
done
doneDas Skript öffnet hierbei mittels tail das Access-Log und folgt diesem. Logrotates und Verschiebungen werden ebenfalls berücksichtigt und im Anschluss gefolgt. Existiert ein Logfile noch nicht, wird nach dem Anlegen auch dieses erkannt und herangezogen (-F und –retry).
Nach der Pipe wird mittels Grep auf den HTTP-Code 200 geprüft und nur Zeilen mit erfolgreichem Aufruf von / ermittelt. Dies kann auch ein gänzlich anderer Pfad wie zum Beispiel /auth-xyz sein. Je nach persönlichem Empfinden.
Die IP-Adresse wird im Anschluss ermittelt und an nft übergeben. Der Befehl schreibt die IP-Adresse anschließend mit einem Timeout von 24 Stunden in das Set myset.
In NFTables sollte dieses Set vorab existieren und deshalb in der Konfiguration hinterlegt werden! Außerdem muss das Set noch in Firewall-Regeln hinterlegt werden!
table inet filter {
set myset {
type ipv4_addr
flags timeout
}
.....
}Im Nginx sollte dann auf dem vHost (my-host) zum Beispiel ein Basic Auth aktiviert werden. Benutzer die sich nicht korrekt anmelden werden eine 403 Meldung zurückbekommen, während korrekt Authentifizierte Benutzer einen 200er Code erhalten.
Diese Meldungen erscheinen im Log und werden anschließend verarbeitet.
Firewall-Beispiele mit Firewalld
Warning
Fehlerhafte Konfigurationen können zu Netzwerkstörungen führen!
Docker auf externe Netze beschränken
Zuerst wird ein IPSet angelegt. Dies kann als XML File passieren oder mittels Befehlen:
<?xml version="1.0" encoding="utf-8"?>
<ipset type="hash:ip">
<entry>10.0.0.0/8</entry>
<entry>172.16.0.0/12</entry>
<entry>192.168.0.0/16</entry>
</ipset>
# fügt ein neues IPSET der Konfiguration hinzu
firewall-cmd --permanent --new-ipset=RFC_1819 --type=hash:ip
# private IP-Adressen hinzufügen
firewall-cmd --permanent --ipset=RFC_1819 --add-entry=10.0.0.0/8
firewall-cmd --permanent --ipset=RFC_1819 --add-entry=172.16.0.0/12
firewall-cmd --permanent --ipset=RFC_1819 --add-entry=192.168.0.0/16
# oder entfernen / löschen
firewall-cmd --permanent --ipset=RFC_1819 --remove-entry=10.0.0.0/8
firewall-cmd --permanent --delete-ipset testNach der Konfiguration ist das Set noch nicht geladen. Also fügen wir noch die Firewall-Regel (Policy) hinzu.
Grundsätzlich können Rules viele Einstellungen abbilden, aber keine Ziel-Adressen mittels IPSETs, deshalb wird eine Firewalld Policy verwendet:
<?xml version="1.0" encoding="utf-8"?>
<!-- Standardverfahren ist REJECT, kann aber auch DROP gesetzt werden -->
<policy target="REJECT">
<!-- IPAdressen von Docker werden maskiert (Source NAT) -->
<masquerade/>
<!-- falls ein lokaler DNS Resolver verwendet wird, sollte Port 53 erlaubt werden -->
<rule family="ipv4">
<destination ipset="RFC_1819"/>
<port port="53" protocol="udp"/>
<accept/>
</rule>
<rule family="ipv4">
<destination ipset="RFC_1819"/>
<port port="53" protocol="tcp"/>
<accept/>
</rule>
<!-- IP-Adressen die nicht im IPSET RFC_1819 sind, werden erlaubt -->
<rule family="ipv4">
<destination ipset="RFC_1819" invert="True"/>
<accept/>
</rule>
<!-- aus Zone docker -->
<ingress-zone name="docker"/>
<!-- an Zone public oder home -->
<egress-zone name="public"/>
<egress-zone name="home"/>
</policy>Wichtig hierbei ist, dass die Docker Bridge (hier docker0) sich in der Zone docker befindet und das ausgehende Interface in home oder public. Dies dies nicht der Fall, muss die Konfiguration angepasst werden.
Die Zone docker kann angelegt werden:
<?xml version="1.0" encoding="utf-8"?>
<zone target="DROP">
<interface name="docker0"/>
<source address="172.17.0.1/16"/>
</zone>Grundsätzlich werden Verbindungen von diesem Interface verworfen (DROP), wodurch kein Container auf den Docker-Host selbst zugreifen kann.
Sollte dies nicht gewünscht sein, muss die Konfiguration angepasst werden…
Reload
firewall-cmd --reloadNetplan, Systemd Dummy-Interface
Vorwort
Nach einigen Recherchen hat sich herausgestellt, dass Netplan in der aktuellen Version (Stand heute) keine Dummy Interfaces anlegen kann (siehe Link unten).
Netplan hat es endlich geschafft und kann Dummy Interfaces \o/
Also gibt es nun 2 Anleitungen für Netplan und Systemd.
Dummy Interfaces vorab anlegen
Die Dummy-Interfaces werden von einem Kernel Modul bereitgestellt, welches im Regelfall erst geladen wird, wenn es notwendig ist.
Durch die Hinzugabe von Parametern lassen sich bereits beim Laden mehrere Schnittstellen anlegen. Diese werden der Menge nach durchnummeriert.
Dies ist für die Anleitung absolut nicht notwendig, möchte ich aber mal erwähnt haben (“unnützes” Zusatzwissen)
modprobe dummy numdummies=5
$ ip -o link | grep dummy
44572: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000\ link/ether 72:a0:77:02:5e:57 brd ff:ff:ff:ff:ff:ff
44573: dummy1: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000\ link/ether 36:dd:a2:0c:81:d0 brd ff:ff:ff:ff:ff:ff
44574: dummy2: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000\ link/ether 1e:f3:22:bc:6a:74 brd ff:ff:ff:ff:ff:ff
44575: dummy3: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000\ link/ether 56:ef:c3:3b:9a:b9 brd ff:ff:ff:ff:ff:ff
44576: dummy4: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000\ link/ether 5a:92:bf:48:9f:82 brd ff:ff:ff:ff:ff:ffDummy via Systemd-Networkd
Anlegen der Dummy-Schnittstelle
# File: /etc/systemd/network/99-dummy10.netdev
[NetDev]
Name=dummy10
Kind=dummyKonfiguration der IP-Adresse(n)
Dieser Schritt ist nicht zwingend nötig, da die Konfiguration der IP-Adresse auch via Netplan erfolgen kann.
# File: /etc/systemd/network/99-dummy10.network
[Match]
Name=dummy10
[Network]
Address=10.10.10.33/24Laden der Interfaces
systemctl reload systemd-networkdDummy via Netplan
Gemäß der offiziellen Doku https://netplan.readthedocs.io/en/stable/netplan/#properties-for-device-type-dummy-devices:
network:
dummy-devices:
dummy0:
addresses:
- 192.168.0.123/24
dummy1:
addresses:
- 192.168.1.123/24
...Im Anschluss Netplan laden:
netplan applyLinks
-
Systemd-Networkd Dokumentation im Archlinux Wiki (deutsch)
https://wiki.archlinux.de/title/Systemd/systemd-networkd -
offizielle Doku von Systemd-Networkd
https://www.freedesktop.org/software/systemd/man/systemd.network.html -
offizielle Projekt-Seite von netplan
https://netplan.io/ -
Bug Report zum Support von Dummy Interfaces
https://bugs.launchpad.net/netplan/+bug/1774203
VPN
Subsections of VPN
Wireguard Clients durch NordVPN tunneln
Idee
NordVPN bietet für die Verbindung diverse Anwendungen / Apps an. Möchte (oder kann) man diese nicht nutzen, weil das Endgerät dies zum Beispiel nicht unterstützt, gibt es zusätzlich noch Alternativen wie OpenVPN, IPSec oder Wireguard. Für die Menge der verfügbaren Server stehen dann entsprechende Konfigurationen bereit.
Das hier beschriebene Setup bietet folgende Vorteile:
- Webinterface zur Verwaltung der Clients
- jedes Endgerät hat einen eigenen Schlüssel, der unabhängig von den anderen Geräten entzogen werden kann
- einfache Einbindung von Geräten über einen Wireguard-Client
- ermöglicht Split-Tunnelling
- regelmäßiger Wechsel des aktiven Nordvpn-Servers (Container kann sich neu verbinden)
Zusammenfassung der Schritte
- NordVPN Token generieren
- private Key auslesen (mithilfe des Tokens)
- Docker-Compose Umgebung konfigurieren
- Skripte anlegen
- starten
Einrichtung
Docker / Compose installieren
# Ubuntu
apt-get install docker.io docker-compose
# Archlinux
pacman -Syu docker docker-composePrivate Key auslesen
temporärer Token
Der hier generierte Token sollte im Anschluss wieder gelöscht werden!
private Key
Der hier ausgelesene “private key” ist accountweit gültig und darf Dritten nicht zugänglich gemacht werden!
Bevor der “Private Key” für die eigentliche Verbindung ausgelesen werden kann, benötigen wir ein temporärer Token zum einmaligen verbinden:
Nun erstellen wir einen Container der mittels Token einloggt, eine NordLynx Verbindung herstellt und den dazu verwendeten Private Key zurückgibt:
TOKEN=<NORDVPN TOKEN>
docker run --rm --cap-add=NET_ADMIN --name nordvpn_key_fetch \
-e TOKEN=${TOKEN} ghcr.io/bubuntux/nordvpn:get_private_key
<einige Ausgaben später...>
############################################################
IP: 10.5.0.2/32
Private Key: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
\(^O^)/
############################################################docker-compose.yml Konfiguration
Client Netzwerkeinstellung
Bitte die Kommentare oberhalb WG_ALLOWED_IPS beachten und die unerwünschte Konfiguration entfernen (auskommentieren)!
Mit ein wenig Phantasie lässt sich erkennen, dass mehrere NordVPN Container gestartet und mit Wireguard Containern verbunden werden können.
Hierbei ist allerdings nur eine Verbindung pro NordVPN Container möglich.
Möchte man mehr Verbindungen (z.B. pro Land / Kontinent) nutzen, benötigt man mehrere NordVPN-Container!
Die Variablen werden in der docker-compose.yml erklärt:
version: "3.8"
services:
nvpn_01:
container_name: "wgeasy_nvpn_01"
image: ghcr.io/bubuntux/nordlynx
restart: unless-stopped
environment:
# privater Schlüssel zum Verbindung zu NordVPN Lynx (vorher ausgelesen)
PRIVATE_KEY: "<SUPER_GEHEIMES_NORDVPN_SECRET>"
# Subnetz des Wireguard Servers, muss mit WG_DEFAULT_ADDRESS zusammenpassen!
NET_LOCAL: "192.168.33.0/24"
# IP-Adresse des wg-Containers (siehe wg01.networks.default.ip4_address)
WG_CONTAINER_IP: "172.18.18.11"
# Skript mit Anpassungen, damit die Wireguard Clients erreicht werden
PRE_UP: "/hooks/pre_connect.sh"
# optional um bestimmte Server zu wählen (Beispiel hier ist DE)
#QUERY: 'filters\[country_id\]=81'
volumes:
- /srv/docker/wg_easy/nvpn_01:/hooks:ro
cap_add:
- NET_ADMIN
- NET_RAW
networks:
default:
ipv4_address: 172.18.18.2
wg_01:
container_name: "wgeasy_wg_01"
image: weejewel/wg-easy
ports:
- "51820:51820/udp"
- "51821:51821/tcp"
# FALLS ein Webserver davor geschaltet werden soll, kann dieser Port auch deaktiviert werden und die Container-IP als Ziel für z.B. nginx / Traefik / Apache genutzt werden
# Alternativ bindet man den HTTP Port nur lokal und referenziert diese im Webserver
#- "127.0.0.1:51821:51821/tcp"
environment:
# IP-Adresse des NordVPN-Containers, wird als Router für die Wireguard-Clients genutzt (siehe nvpn_01.networks.default.ipv4_address)
CUSTOM_GW: "172.18.18.2"
# Hostname / IP-Adresse des Servers, wird in der Client Config von Wireguard hinterlegt
WG_HOST: "my.host.com"
# Admin Password für das Webinterface
# Empfehlung: keine Sonderzeichen, könnte (!) zu Fehlern führen
PASSWORD: "<MEIN_SUPER_SICHERES_KENNWORT>"
# Subnetz für Wireguard-Clients, MUSS mit NET_LOCAL von NordVPN zusammenpassen!
# x wird von wgeasy ersetzt und muss so bleiben
WG_DEFAULT_ADDRESS: "192.168.33.x"
# DNS Server, wird von den Wireguard-Clients im Tunnel genutzt
WG_DEFAULT_DNS: "1.1.1.1,9.9.9.9"
# Standard MTU ist 1500, da Pakete durch einen Tunnel müssen, benötigen wir eine kleinere MTU
WG_MTU: "1420"
# alle 30 Sekunden wird die Verbindung überprüft
WG_PERSISTENT_KEEPALIVE: "30"
WG_PRE_UP: "/hooks/pre_up.sh"
# optional, nur wenn sich Clients untereinander erreichen können sollen
#WG_POST_UP: "/hooks/post_up.sh"
# hier kann entschieden werden, welche Netzwerke / IPs durch den Tunnel geroutet werden sollen
# WICHTIG: dies wird nur beim Generieren der Client-Config berücksichtigt, spätere Anpassungen haben KEINEN VERÄNDERNDEN Effekt auf bereits generierte Tunnel-Configs!
# nachträgliche Änderungen müssen im Client selbständig nachgepflegt werden, oder der Tunnel neu angelegt und die Config heruntergeladen werden!
# 2 Beispiele:
# ALLE IP-Adressen werden über den Tunnel geroutet, hierbei können auch lokale Adressen möglicherweise nicht mehr erreicht werden (z.B. Drucker, Handys, ...)
# sollte es zu Problemen kommen, das Netz 0.0.0.0/0 im Client hinterlegen (aus Gründen der Kompatibilität mit manchen Betriebssystemen wurde dieses hier in 2 x /1 geteilt)
WG_ALLOWED_IPS: "0.0.0.0/1,128.0.0.0/1"
# Sollen private IP-Adressen ausgenommen werden (10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16):
WG_ALLOWED_IPS: "0.0.0.0/5,8.0.0.0/7,11.0.0.0/8,12.0.0.0/6,16.0.0.0/4,32.0.0.0/3,64.0.0.0/2,128.0.0.0/3,160.0.0.0/5,168.0.0.0/6,172.0.0.0/12,172.32.0.0/11,172.64.0.0/10,172.128.0.0/9,173.0.0.0/8,174.0.0.0/7,176.0.0.0/4,192.0.0.0/9,192.128.0.0/11,192.160.0.0/13,192.169.0.0/16,192.170.0.0/15,192.172.0.0/14,192.176.0.0/12,192.192.0.0/10,193.0.0.0/8,194.0.0.0/7,196.0.0.0/6,200.0.0.0/5,208.0.0.0/4,224.0.0.0/3"
volumes:
# wird durch das Webinterface beschrieben, deswegen rw!
- /srv/docker/wg_easy/wg_01_config:/etc/wireguard:rw
- /srv/docker/wg_easy/wg_01_hooks:/hooks:ro
restart: unless-stopped
cap_add:
- NET_ADMIN
- SYS_MODULE
sysctls:
- net.ipv4.ip_forward=1
- net.ipv4.conf.all.src_valid_mark=1
networks:
default:
ipv4_address: 172.18.18.11
networks:
default:
driver: bridge
ipam:
driver: default
config:
- subnet: 172.18.18.0/24
driver_opts:
com.docker.network.bridge.name: br_wgeasyNordVPN Hook Skript
Der Befehl legt ein Skript für den NordVPN Container an, welches vor der Verbindungsherstellung durchgeführt wird.
Hierbei wird die Route zu den WG-Clients ausgetausch, wodurch diese über den WG-Container erreicht werden.
#File: /srv/docker/wg_easy/nvpn_01/pre_connect.sh
#!/bin/bash
# löschen der existierenden Route von NordPVN
ip route del $NET_LOCAL
# Route um das Wireguard-Netz über wgeasy Container zu routen
ip route add $NET_LOCAL via $WG_CONTAINER_IPWG-Easy Hook
Wird vorm Start des Wireguard-Servers ausgeführt um die Umgebung abzusichern und das Routing via NordVPN vorzubereiten. Ist NordVPN nicht aktiv, besteht keine Möglichkeit in das Internet zu routen. Dies ist aber ein gewünschter Nebeneffekt.
Note
Das wg-easy Webinterface ist nur über den Docker-Host erreichbar, wenn dies nicht gewünscht ist, müssen Anpassungen (siehe optionale Freigaben) erfolgen!
#File: /srv/docker/wg_easy/wg_01_hooks/pre_up.sh
#/bin/bash
set -e
# Netzwerk und Standard-Gateway auslesen
NETWORK=${WG_DEFAULT_ADDRESS/.x/.0/24}
GW=$(/sbin/ip route | awk '/default/ { print $3 }')
# Webinterface vom Server erlaubt
iptables -I INPUT -s ${GW} -p tcp --dport 51821 -j ACCEPT
# optionale Freigaben
# Webinterface durch Wireguard Clients
#iptables -I INPUT -s ${NETWORK} -p tcp --dport 51821 -j ACCEPT
# Webinterface von überall erreichbar
#iptables -I INPUT -p tcp --dport 51821 -j ACCEPT
# DNS im Container erlauben
iptables -I INPUT -i lo -s 127.0.0.1 -j ACCEPT
# existierende Verbindungen werden erlaubt
iptables -I INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
# Standard-Regel ist das Verwerfen von Paketen, Accept wird von wg-easy später hinterlegt!
iptables -P INPUT DROP
iptables -P FORWARD DROP
# wg-easy legt eine masquerade (Source-Nat) Regel an, diese hebeln wir aus, damit im Nordvpn Container die Tunnel-IP-Adresse des Clients ersichtlich ist und nicht zwischen den Containern NAT betrieben wird
iptables -t nat -I POSTROUTING -j ACCEPT
# Pakete von WG-Clients werden durch eine gesonderte Routing-Tabelle behandelt, damit diese in den NordVPN Container geroutet werden
# Dies ist notwendig, damit der wg-easy Container selbst ein Gateway hat und das Webinterface erreichbar ist
# Routen für IP-Pakete von WG-Clients werden in Tabelle 1000 gesucht
ip rule add from ${NETWORK} lookup 1000
# Standard-GW für Tunnel-Clients über den NordVPN Container
ip route add default via ${CUSTOM_GW} table 1000
# alle privaten Netze werden geblockt, denn diese sollen nicht über NordVPN geroutet werden!
# weitere IP-Adressen (/32) oder Netze können hier hinterlegt
# Außerdem wird somit zusätzlich sichergestellt, dass WG-Clients sich untereinander nicht erreichen können.
# Sollen sich WG-Clients untereinander erreichen, kann im post_up.sh dies konfiguriert werden
ip route add blackhole 10.0.0.0/8 table 1000
ip route add blackhole 172.16.0.0/12 table 1000
ip route add blackhole 192.168.0.0/16 table 1000
# eventuell andere lokale IP-Adressen auf dem WG Host wie Pihole, oder als exklude vom VPN Tunnel
# ip route add x.x.x.x via ${GW} table 1000Das post_up.sh Skript ist optional!
#File: /srv/docker/wg_easy/wg_01_hooks/post_up.sh
#/bin/bash
set -e
# optionale Route (Wireguard Clients können sich untereinander erreichen)
# Diese Regel muss in der post_up.sh stehen, weil pre_up.sh vor Erstellung des Wireguard Interfaces ausgeführt wird.
# Das hat zur Folge dass die Regel nicht angelegt wird ("no such device / interface")
ip route add ${NETWORK} dev wg0 table 1000Nachbereitung der Hook Scripts
cd /srv/docker/wg_easy/
# Berechtigung der Skripts anpassen, damit diese ausführbar sind
find . -name "*.sh" -exec chmod +x {} \;Container start
cd /srv/docker/wg_easy/
docker-compose up -dIm Anschluss sollten die beiden Container gestartet werden.
Ob das Webinterface direkt erreichbar ist, hängt stark von der gewählten Konfiguration ab …
Warning
Ich rate dringend zur Absicherung des Webinterfaces! Beispiele:
- Reverse-Proxy (z.B. nginx) und das Webinterface per SSL absichern
- Interface nur lokal vom Server verfügbar machen und mittels SSH Tunnel zuzugreifen!
Anleitung zum Thema SSH-Tunneling
Ignoriert man alle Warnungen und macht das Webinterface öffentlich erreichbar, wäre es hier zu erreichen: http://my.host.com:51821/
(my.host.com muss durch die IP-Adresse des Hosts ersetzt werden!)
Tipps & Tricks
NordVPN Server finden
Die hier hinterlegte Liste kann sich zwischenzeitlich ändern, daher ist eine eigene Abfrage ratsam…
docker run --name nvpn_temp -ti --rm --entrypoint /bin/bash ghcr.io/bubuntux/nordlynx:latest
curl "https://api.nordvpn.com/v1/servers/countries" | jq -r '.[] | "\( .name ) \( .id )"'Erklärungen
Split-Tunneling
Es kann entschieden werden, welcher Traffic durch den VPN-Tunnel geroutet wird und welcher nicht. Es wird also nicht per se der komplette Netzwerkverkehr durch den Tunnel geroutet.
Referenzen
Nutzung der NordVPN API
https://sleeplessbeastie.eu/2019/02/18/how-to-use-public-nordvpn-api/
Docker Container (bubuntux)
Wake On LAN mit MQTT auslösen
Broadcast
Diese Anleitung setzt einen funktionierenden MQTT Service (z.B. Mosquitto) voraus!
Vorwort / Idee
Wake On LAN ist eine gängige Praxis um Geräte über das Netzwerk einzuschalten. In den meisten Fällen funktioniert dies allerdings nur in der selben Layer2-Domäne. Ist der auslösende Server / Dienst isoliert, kann dieser Geräte aus anderen Netzwerken nicht aktivieren.
Ein konkretes Szenario könnte sein:
- LG TV (wird mit WOL angeschaltet)
- HomeAssistant ist in einem isolierten Docker-Netzwerk, somit einer eigenen Layer2-Domäne
Anstatt HomeAssistant in das interne Netz (per Host-Network oder entsprechendem Interface) zu packen, kann das Senden von WOL-Paketen auch über ein Python-Script erfolgen.
Dieses hat ein Bein im benötigen Netzwerk und kann WOL Pakete hinein senden.
Grundsätzlich ist dieses Konstrukt nicht auf HomeAssistant beschränkt und kann auch zum steuern mehrerer Netzwerke angewendet werden, die man zentral steuern möchte…
Funktionsweise
graph LR;
A[HomeAssistant] --> |sendet MAC-Adresse an Topic wol-proxy/command| B(MQTT Service 192.168.1.55)
D(MQTT Service TOPIC: wol-proxy/command) --> |liest MAC-Adresse aus Topic wol-proxy/command| C[Python Daemon]
C[Python Daemon] --> |WOL Magic Paket via Broadcast| E(LG TV)
C[Python Daemon] --> |Status schicken in Topic wol-proxy/status| D(MQTT Service)
Docker Image bauen
Ich möchte kein öffentliches Image anbieten, weil der bau einfach ist und fix lokal erfolgen kann.
Es wird LinuxServer.IO als Basis verwendet, Python installiert und die nötigen Python-Pakete installiert.
git clone https://github.com/dr3st/WOL-proxy
cd WOL-proxy
docker build -t wol-proxy:latestKonfiguration
Ich verwende docker-compose um den Dienst zu starten. Die IP-Adressen und Logindaten müssen auf die lokalen Gegebenheiten angepasst werden!
Broadcast
WOL_BROADCAST_ADDR muss die Broadcast-Adresse (letzte IP-Adresse des Netzwerks) sein, keine Geräte-IP!
version: "3"
services:
wol-proxy:
image: wol-proxy:latest
container_name: wol-proxy
network_mode: host
environment:
MQTT_BROKER_HOST: "192.168.1.55"
WOL_BROADCAST_ADDR: "10.44.33.255"
MQTT_USERNAME: "wol"
MQTT_PASSWORD: "REPLACE_PASSWORD"
MQTT_TOPIC_PREFIX: "wol-proxy"
MQTT_CLIENT_ID: "wol"
restart: unless-stoppedStart
docker-compose up -dErzeugung eines WOL Pakets
Zum Erzeugen eines WOL-Pakets muss die MAC-Adresse als Message in das Topic wol-proxy/command geschrieben werden.
HomeAssistant kann dies übernehmen, weil es eine MQTT Integration hat.
Nutzt man beispielsweise bereits Z2M (Zigbee2MQTT), ist die Integration schon gegeben, ansonsten nachlesen wie es einzurichten ist.
Die MAC-Adresse des einzuschaltenden Geräts kann folgenden Format haben:
- aa:bb:cc:dd:ee:ff
- aa-bb-cc-dd-ee-ff
- aa.bb.cc.dd.ee.ff
Anmerkung
Möchte man mehrere Layer2 Netze mit diesem System steuern, kann in jedes Netz ein Python Daemon (Docker Container) eingebunden werden.
Jeder Daemon sollte dann einen eigenen MQTT Topic Prefix erhalten, damit dieser nur Nachrichten die für sein Netz vorgesehen sind verbeitet.
So kann aus einer zentralen MQTT Stelle jedes Netz mit WOL Nachrichten versehen werden und man spart sich Konfigurationen wie L2 Proxies oder Re-Transmissions die einige Router / Firewalls anbieten…
Links
-
Fork mit Docker
https://github.com/dr3st/WOL-proxy -
original Projekt
https://github.com/seanauff/WOL-proxy